


An international research team led by the University of Hong Kong (HKU) developed a new method to accurately track the spread of COVID-19 using population flow data and establishing a new risk assessment model to identify high-risk locales of COVID-19 at an early stage.
This new system serves as a valuable toolkit to public health experts and policymakers in implementing infectious disease control during new outbreaks. The study findings have been published in the journal Nature today (April 29).
The team used nation-wide data provided by a major national carrier in China to track population movement out of Wuhan between 1 January and 24 January 2020, a period covering the annual Chunyun mass migration before the Chinese Lunar New Year to a lockdown of the city to contain the virus.
The movement of over 11 million people travelling through Wuhan to 296 prefectures in 31 provinces and regions in China were tracked.
Differing from usual epidemiological models that rely on historical data or assumptions, the team used real-time data about actual movements focusing on aggregate population flow rather than individual tracking. The data include any mobile phone user who had spent at least 2 hours in Wuhan during the study period.
Locations were detected once users had their phones on. As only aggregate data was used and no individual data was used, there was no threat to consumer privacy.
Combining the population flow data with the number and location of COVID-19 confirmed cases up to 19 February 2020 in China, the team showed that the relative quantity of human movement from the disease epicentre, in this case, Wuhan, directly predicted the relative frequency and geographic distribution of the number of COVID-19 cases across China.
The researchers found that their model can explain 96% of the distribution and intensity of the spread of COVID-19 across China statistically.
The research team then used this empirical relationship to build a new risk detection toolkit. Leveraging on the population flow data, the researchers created an “expected growth pattern” based on the number of people arriving from the risk source, i.e. the disease epicentre.
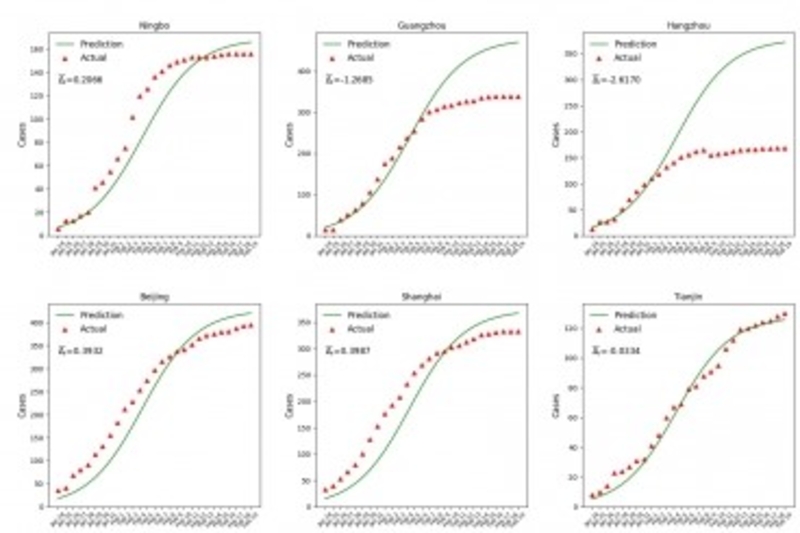
The team thereby developed a new risk model by contrasting the expected growth of cases against the actual number of confirmed cases for each city in China, the difference being the “community transmission risk”.
If there are more reported cases than the model expected, there is a higher risk of community spread. If there are fewer reported cases than the model expected, it means that the city’s preventive measures are particularly effective, or it can indicate that further investigation by central authorities is needed to eliminate possible risks from inaccurate measurement.
What is innovative about the team’s approach is that they use misprediction to assess the level of community risk. Our model accurately tells us how many cases we should expect given travel data.
They contrast this against the confirmed cases using the logic that what cannot be explained by imported cases and primary transmissions should be community spread.
The approach is advantageous because it requires no assumptions or knowledge of how or why the virus spreads, is robust to data reporting inaccuracies, and only requires knowledge of the relative distribution of human movement. It can be used by policymakers in any nation with available data to make rapid and accurate risk assessments and to plan allocation of limited resources ahead of ongoing disease outbreaks.
The team’s research indicates that the geographic flow of people outperforms other measures such as population size, wealth or distance from the risk source to indicate the gravity of an outbreak.












